1. Contexte et défi
Nous devions extraire des données d’un poste de travail sans connexion externe. La seule méthode possible consistait à photographier l’écran. Le document à exfiltrer fait 7 Mo de données binaires, ce qui rend la tâche difficile.
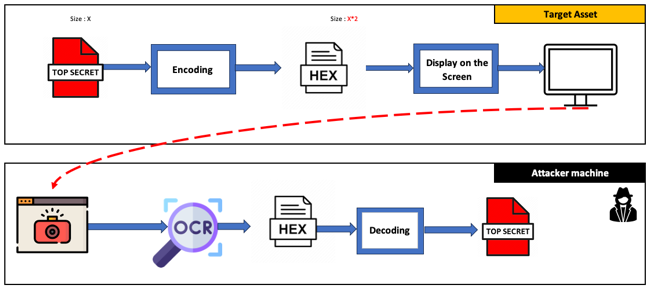
2. Première tentative
Conversion des données en hexadécimal puis utilisation de Tesseract pour l’OCR. Bien que le taux de réussite atteigne 99 %, de nombreux caractères étaient mal reconnus selon leur position.

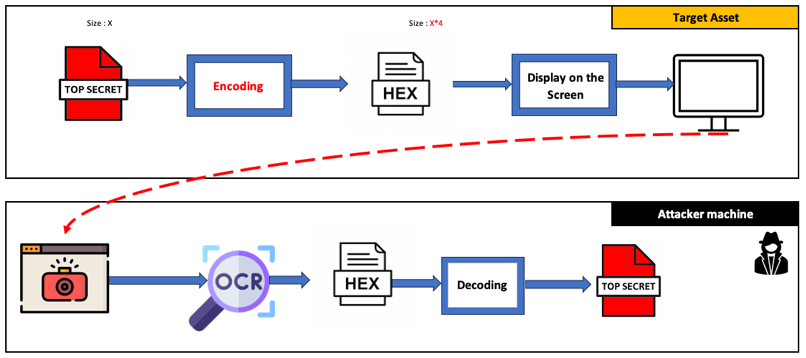
3. Deuxième tentative
Ajout d’espaces autour de chaque caractère pour améliorer la reconnaissance. Cette approche a quadruplé la taille du document et le taux de réussite est tombé à moins de 25 %.

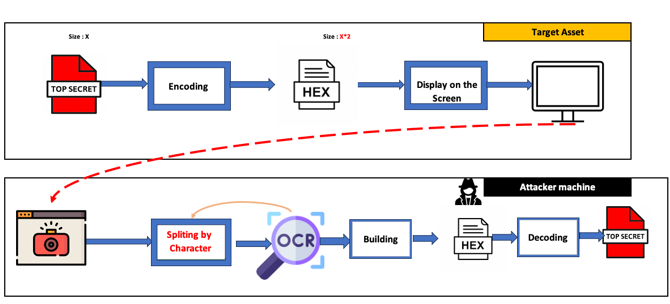
4. Troisième tentative
Découper l’image en petits morceaux contenant un seul caractère a légèrement amélioré la précision, mais pas suffisamment pour un résultat fiable.

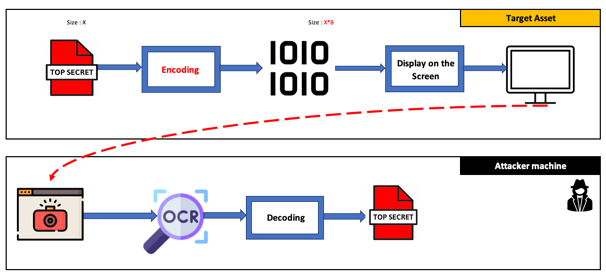
5. Quatrième tentative
Pour réduire l’ensemble de caractères, nous avons choisi un encodage binaire pur, multipliant la taille du fichier par huit mais obtenant une reconnaissance complète sur de petites données.
6. Atteindre l’objectif
Pour de plus gros fichiers, nous avons scindé l’encodage en segments affichés successivement et filmé l’écran avant de reconvertir chaque image en texte.
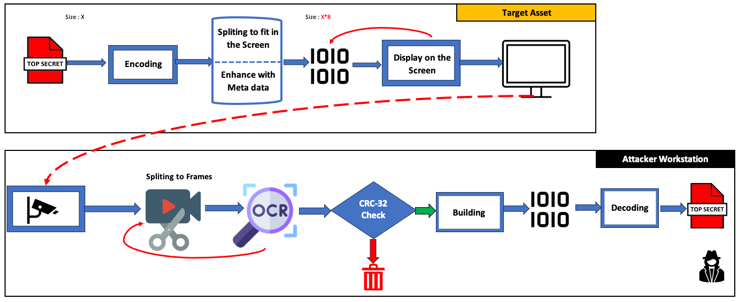
7. Conclusion
Cette méthode d’exfiltration présente de nombreuses limites :
- Processus chronophage – l’encodage et l’enregistrement prennent plusieurs heures.
- Effort manuel – de nombreux scripts doivent être écrits et exécutés.
- Lenteur générale – le procédé reste trop long pour un attaquant pressé.
- Dépendance au réseau – la qualité d’enregistrement peut varier selon la connexion.
Bien que techniquement possible, l’exfiltration par capture vidéo ou photo reste peu pratique pour des volumes importants.